

Autoscaling in Kubernetes
Whenever there is unusual traffic we can scale our deployments accordingly but monitoring our traffic continuously and manually scaling our application to handle such traffic spikes is a tedious process what if there is a way to monitor our pods and scale them automatically Whenever there is an increase in CPU usage memory or some other metric like queries per second this is called Autoscaling.
Kubernetes can do the job for us not only pods if you are running on cloud infrastructure Kubernetes can spin up additional nodes if the existing nodes don't accept any more pods.
Kubernetes offers three types of Auto scalers
Horizontal pod Auto scalar
Vertical pod Auto scaler
Cluster Auto scaler
Horizontal Pod Autoscaler
Horizontal pod Auto scaler increases the number of replicas Whenever there is a spike in CPU memory or some other metric that way the load is distributed among the pods.
How does Kubernetes know when to scale up or when to scale down?
A deployment for that Kubernetes offers a resource named horizontal pod Auto scaler.
Deployment File
apiVersion: apps/v1
kind: Deployment
metadata:
name: utility-api
spec:
replicas: 2
selector:
matchLabels:
app: utility-api
template:
metadata:
name: utility-api-pod
labels:
app: utility-api
spec:
containers:
- name: utility-api
image: pavanelthepu/utility-api
ports:
- containerPort: 8080
resources:
requests:
memory: 20Mi
cpu: "0.25"
limits:
memory: 400Mi
cpu: "1"
service.yml
apiVersion: v1
kind: Service
metadata:
name: utility-api-service
spec:
selector:
app: utility-api
ports:
- port: 8080
targetPort: 8080
HorizontalPodAutoscaler YAML
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: utility-api
spec:
minReplicas: 1
maxReplicas: 5
metrics:
- resource:
name: cpu
target:
averageUtilization: 70
type: Utilization
type: Resource
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: utility-api
After that run this commands
kubectl apply -f deployment.yaml
kubectl apply -f service.yaml
kubectl apply -f hpa.yaml
The first command will apply the deployment.yaml file, which creates a Deployment resource.
The second command will apply the service.yaml file, which creates a Service resource.
The third command will apply the hpa.yaml file, which creates a HorizontalPodAutoscaler resource.
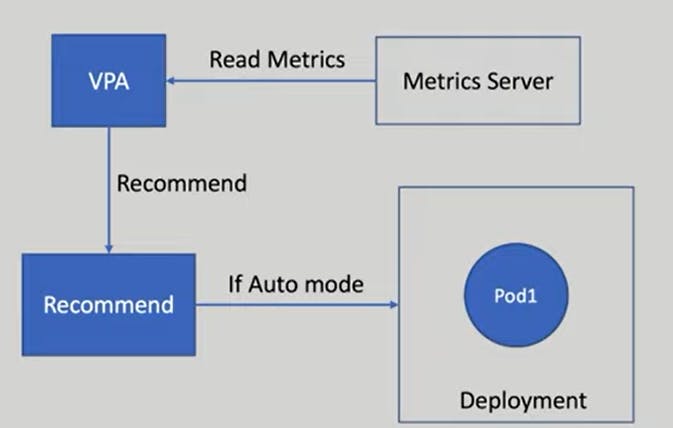
Vertical Pod Autoscaler
Increasing the number of PODS is called scaling up
With vertical pod Autoscaler, we can analyze the resources of deployment and adjust them accordingly to handle the load. Vertical pod Auto scalar we increase the resources of existing pods instead of creating new pods.
Without a vertical pod Auto scaler
If we over-allocate the resources with request and limit our cost increases if they are not fully used.
If we under allocate the resources and they are full our application performance will suffer and the kubelet May kill the pods.
Vertical pod AutoScaling helps us to solve these two issues
Vertical pod auto scaler performs three steps first it reads the resource Matrix of our deployment similar to the HPA based on these metrics it recommends the resource requests and if we prefer to auto-update it updates the resources.
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: utility-api
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: utility-api
updatePolicy:
updateMode: "Off"
This is a Kubernetes YAML configuration file for creating a VerticalPodAutoscaler resource. This resource is used to automatically adjust the resource requests and limits of containers within a pod based on usage. It can horizontally scale containers within a pod by changing their resource requests and limits.
In this example, the VerticalPodAutoscaler is targeting a Deployment resource named utility-api with the apiVersion of apps/v1.
The updatePolicy field specifies how the VerticalPodAutoscaler should update the pod's resource requests and limits.
In this example, the update mode is set to "Off", which means that the VerticalPodAutoscaler will not update the resources automatically.
Install Vertical Pod Auto scalar
step 1. clone repo = git clone https://github.com/kubernetes/autoscaler.git
step 2. Run this cmd = ./vertical-pod-autoscaler/hack/vpa-up.sh
Then
kubectl apply -f vpa.yaml
Cluster Autoscaler
We should be able to add nodes to the cluster automatically to accommodate the more PODS cluster Auto scalar can do the job for us it adds the nodes to the cluster if there are any pods stuck in a pending State because of lack of resources in the cluster.
The Cluster Autoscaler is a tool that helps manage node groups in Kubernetes clusters. It periodically checks for any un-schedulable parts every 10 seconds. When one or more unschedulable parts are detected, the Autoscaler will run an algorithm to decide how many nodes are necessary to deploy all pending parts and what type of nodes should be created. Similarly, the Autoscaler decides to remove a node every 10 seconds only when the resource utilization falls below 50 percent. If the Autoscaler detects one pod in an unscalable state, it will create a new node, and the scheduler will automatically schedule the unscalable pod onto the new node. This helps ensure that the cluster is always running optimally, with the right number of nodes to handle the workload.
The cluster Auto scaler doesn't look at the memory or CPU available when it triggers the auto-scaling it looks at the unscalable pods.
These three Auto scalers can scale down also means decreasing the number of Pods, decreasing the resources and decreasing the number of nodes when there is no load.
Kubernetes Cluster Upgrade
Upgrade master
Upgrading the control plane consist of the following steps:
Upgrade kubeadm on the Control Plane node
Drain the Control Plane node
Plan the upgrade (kubeadm upgrade plan)
Apply the upgrade (kubeadm upgrade apply)
Upgrade kubelet & kubectl on the control Plane node
Uncordon the Control Plane node
- Determine which version to upgrade to
apt update
apt-cache madison kubeadm
- On the control plane node, run:
kubeadm upgrade plan
Upgrading kubeadm tool
apt-mark unhold kubeadm && \ apt-get update && apt-get install -y kubeadm=1.26.3-00 && \ apt-mark hold kubeadmVerify that the download works and has the expected version:
kubeadm versionDrain the control plane node:
# replace <Node-Name> with the name of your control plane node $ kubectl drain <Node-Name> --ignore-daemonsets --delete-local-dataOn the control plane node, run:
kubeadm upgrade planOn the control plane node, run:
kubeadm upgrade apply v1.26.3Un cordon the control plane node:
$ kubectl uncordon <node name> $ kubectl uncordon masterUpgrade kubelet and kubectl
$ apt-mark unhold kubelet kubectl && \ apt-get update && apt-get install -y kubelet=1.26.3-00 kubectl=1.26.3-00 && \ apt-mark hold kubelet kubectlRestart the kubelet
$ systemctl daemon-reload
$ systemctl restart kubelet
- Check Version
$ kubectl get nodes
The Master is Updated.......
Upgrade Node
Upgrading the worker nodes consist of the following steps:
Drain the node
Upgrade kubeadm on the node
Upgrade the kubelet configuration (kubeadm upgrade node)
Upgrade kubelet & kubectl
Uncordon the node
- Check the Version of the worker node From master machine
Kubectl get nodes
- Upgrade Kubeadm perform this on Worker Machine
apt-mark unhold kubeadm && \
apt-get update && apt-get install -y kubeadm=1.26.3-00 && \
apt-mark hold kubeadm
Drain the Worker Node (perform this on master Machine)
kubectl drain <node-to-drain> --ignore-daemonsets kubectl drain worker-02 --ignore-daemonsetsUpgrade kubelet config on worker node (perform this on Worker Machine)
kubeadm upgrade nodeUpgrade kubelet and kubectl (perform this on Worker Machine)
apt-mark unhold kubelet kubectl && \ apt-get update && apt-get install -y kubelet=1.18.8-00 kubectl=1.18.8-00 && \ apt-mark hold kubelet kubectlRestart the kubelet
systemctl daemon-reload systemctl restart kubelet- Uncordon the node (perform this on the master Machine)
kubectl uncordon worker-02
- Verify the status of the cluster
kubectl get nodes
Kubernetes Cluster upgraded successfully.
Kubernetes backup & restore
The dynamic nature of Kubernetes environments presents challenges for traditional backup systems and techniques, with stricter requirements for Recovery Point Objective (RPO) and Recovery Time Objective (RTO). To address these challenges, three key features are recommended for enterprise backup solutions, including disaster recovery, backup and restore, and local high availability. These features are considered essential best practices for Kubernetes backups.
Backup and Restore:
The backup process needs to be able to capture and save the entire Kubernetes app, including its configuration, resources, and data, as a single unit for easy restoration. A proper Kubernetes backup system should be able to back up specific applications or groups of applications and the entire Kubernetes namespace. While it is similar to regular backup processes, Kubernetes backup also requires specific features like retention, scheduling, encryption, and tiering for a more efficient backup and restore system
Data types that need to be backed up in Kubernetes
To make it easier, it’s possible to split all of the data and config file types in two different categories: configuration and persistent data.
Configuration (and desired-state information) includes:
Kubernetes etcd database
Docker files
Images from Docker files
Persistent data (changed or created by containers themselves) are:
Databases
Persistent volumes
Kubernetes backup solution market
Kasten K10
Portworx
Cohesity
OpenEBS
Rancher Longhorn
Rubrik
Druva
Zerto
\=============================================================
Connect me on
LinkedIn: https://www.linkedin.com/in/aditya-tak/
Hashnod: https://adityatak.hashnode.dev/
#Kubernetes #Devops #Kubeweek #kubeweekchallenge