


Volumes
Containers are ephemeral. One problem is when the container crashes the data is lost. The kubelet restarts the container but is in a clean state. A second problem occurs when sharing files between containers running together in a pod.
So basically we need a storage that doesn't depend on the pod lifecycle. It will still be there when pod dyes and a new one gets created so the new pod can pick up where the previous one left off so it will read the existing data from that storage to get up-to-date data.
We don't know on which node the new pod restarts so our storage must also be available on all nodes not just one specific one. So that when the new pod tries to read the existing data the up-to-date data is there on any node in the cluster
We need highly available storage that will survive even if the whole cluster crashed.
So the 3 main points are :
1) Storage that doesn't depend on the pod lifecycle.
2) Storage must be available on all nodes.
3) Storage needs to survive even if the cluster crashes.
So these are the criteria or the requirements that our storage for example your database storage will need to have to be reliable
Another use case for persistent storage which is not for databases is a directory maybe you have an application that writes and reads files from a pre-configured directory this could be session files for application or configuration files etc and you can configure any of these types of storage using Kubernetes component called persistent volume.
Persistent volume:
Persist volume is a cluster resource just like RAM or CPU that is used to store data.
Persistent volume just like any other component gets created using Kubernetes YAML file.
-kind PersistenetVolume
-spec: how much storage is needed.
A persistent volume is just an abstract component it must take the storage from the actual physical storage right like the local hard drive from the cluster nodes or your external NFS servers outside of the cluster or maybe cloud storage like AWS block storage.
Where this storage does come from and who makes it available to the cluster?
Kubernetes doesn't care about your actual storage it gives you a persistent volume component as an interface to the actual storage that you as a maintainer or administrator have to take care of so you have to decide what type of storage your cluster services or applications would need and create and manage them by yourself managing meaning do backups and make sure they don't get corrupt etc
So storage in Kubernetes is an external plug-in to your cluster. Whether it's a local storage or a remote storage doesn't matter they're all plugins to the cluster.
You can have multiple storages configured for your cluster where one application in your cluster uses local disk storage and another one uses the NFS server and another one uses some cloud storage or one application may also use multiple of those storage types.
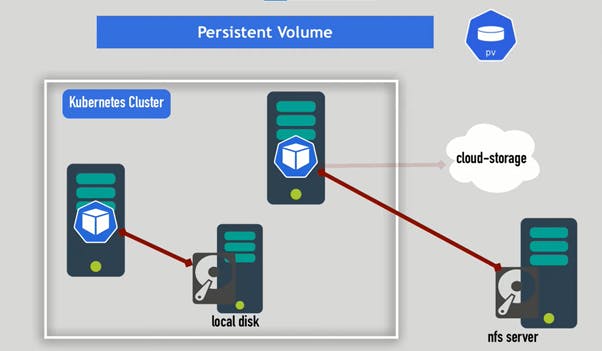
By creating persistent volumes you can use this actual physical storage.
In the persistent volume specification section you can define which storage backend you want to use to create that storage abstraction or storage resource for applications
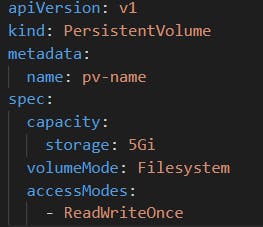
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-name
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
storageClassName: slow
mountOptions:
- hard
- nfsvers=4.0
nfs:
path: /dir/path/on/nfs/server
server: nfs-server-ip-address
So this is an example where we use the NFS storage back-end we define how much storage we need and some additional parameters so that storage should be read, write or read-only and the storage back-end with its parameters.
apiVersion: v1
kind: PersistentVolume
metadata:
name: example-pv
spec:
capacity:
storage: 100Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
- Delete
persistentVolumeReclaimPolicy: Retain
storageClassName: local-storage
local:
path: /mnt/disks/ssd1
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
key: kubernetes.io/hostname
operator: In
values:
- example-node
This is another example of local storage which is on the node itself which has an additional node affinity attribute.
Persistent volumes are not named spaced meaning they're accessible to the whole cluster and unlike other components that we saw like pods and services they're not in any namespace they're just available to the whole cluster to all the namespaces.
LOCAL VS REMOTE VOLUME
Each volume type has its use case!
Local volume types violate 2 Requirements for data persistence:
Being tied to 1 specific node
Surviving cluster crashes
Because of these reasons for database persistence, you should almost always use remote storage.
Persistent Volume Claim
PVCs are also created with YAML configuration.
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: pvc-name
spec:
storageClassName: manual
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
In this YAML file, we've created a PersistentVolumeClaim resource named pvc-name, with a request for 10Gi of storage using the manual storage class. It has a ReadWriteOnce access mode and Filesystem volume mode.
PVC claims a volume with a certain storage size or capacity which is defined in the persistent volume claim and some additional characteristics like access type should be read-only or read rights or the type and whatever persistent volume matches these criteria or in other words, satisfies this claim will be used for the application.
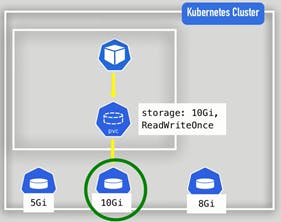
You have to now use that claim in your pod's configuration like this.
Version: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: myfrontend
image: nginx
volumeMounts:
- mountPath: "/var/www/html"
name: mypd
volumes:
- name: mypd
persistentVolumeClaim:
claimName: pvc-name
In this YAML file, we've created a Pod resource named mypod with a single container named myfrontend that uses the nginx image. We've mounted a PersistentVolumeClaim named pvc-name to the container's /var/www/html directory using a volume named mypd.
So in the path specification here you have the volumes attribute that references the persistent volume claim with its name so now the pod and all the containers inside the pod will have access to that persistent volume storage.
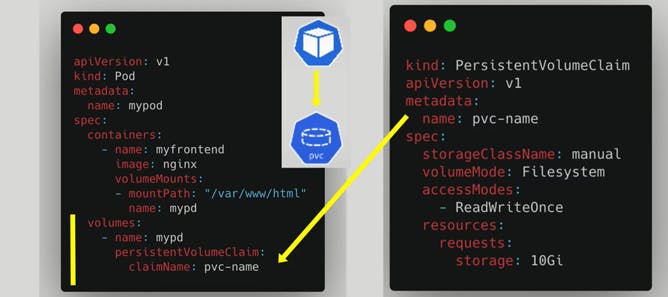
Levels of volume abstractions
Pods access storage by using the claim as a volume.
They request the volume by claiming the claim then go and try to find a volume persistent volume in the cluster that satisfies the claim.
The volume will have storage in the actual storage back-end that it will create that storage resource from.
In this way the pod will now be able to use that actual storage back-end.
(Note: Claims must exist in the same namespace as the pod using the claim)
Once the pod finds the matching persistent volume through the persistent volume claim the volume is then mounted into the pod.
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: myfrontend
image: nginx
volumeMounts:
- mountPath: "/var/www/html"
name: mypd
volumes:
- name: mypd
persistentVolumeClaim:
claimName: pvc-name
Then that volume can be mounted into the container inside the pod.
If you have multiple containers in a pod you can decide to mount this volume in all the containers or just some of those.
Now the container and the application inside the container can read and write to that storage. When the pod dies a new one gets created it will have access to the same storage and see all the changes the previous pod or the previous containers made.
ConfigMap and Secret as volume types
Both of them are local volumes
Not created by a PV and PVC
Managed by Kubernetes itself.
Scenario:
Consider a case where you need a configuration file for your Prometheus pod.
A certificate file for your pod.
In both cases you need a file available to your pod, so how this works?
Create ConfigMap and/or Secret component
Mount that into your pod/container
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: busybox-container
image: busybox
volumeMounts:
- name: config-dir
mountPath: /etc/config
volumes:
- name: config-dir
configMap:
name: bb-configmap
In this YAML file, we've created a Pod resource named mypod with a single container named busybox-container that uses the busybox image. We've mounted a ConfigMap named bb-configmap to the container's /etc/config directory using a volume named config-dir.
Summary
Volume is a directory with some data
These volumes are accessible in containers in a pod
How made available, backed by which storage medium - defined by specific volume types
To use a volume a pod specifies what volumes to provide for the pod in the specification volumes attribute
Inside the pod and you can decide where to mount that storage using volume mounts attribute inside the container section.
Apps can access the mounted data here: "/var/www/html"
The application can access whatever storage we mounted into the container
Storage Class (SC)
To persist data and Kubernetes admins need to configure storage for the cluster to create persistent volumes and developers then can claim them using PVCs
Consider a cluster with hundreds of applications where things get deployed daily and storage is needed for these applications so developers need to ask admins to create persistent volumes they need for applications before deploying them and admins then may have to manually request storage from cloud or storage provider and create hundreds of persistent volumes for all the applications that need storage manually and that can be tedious, time-consuming and can get messy very quickly.
To make this process more efficient there is a third component of Kubernetes persistence called storage class.
Storage class basically creates or provisions persistent volumes dynamically whenever PVC claims it.This way creating or provisioning volumes in a cluster may be automated.
Storage class also created using YAML configuration file.
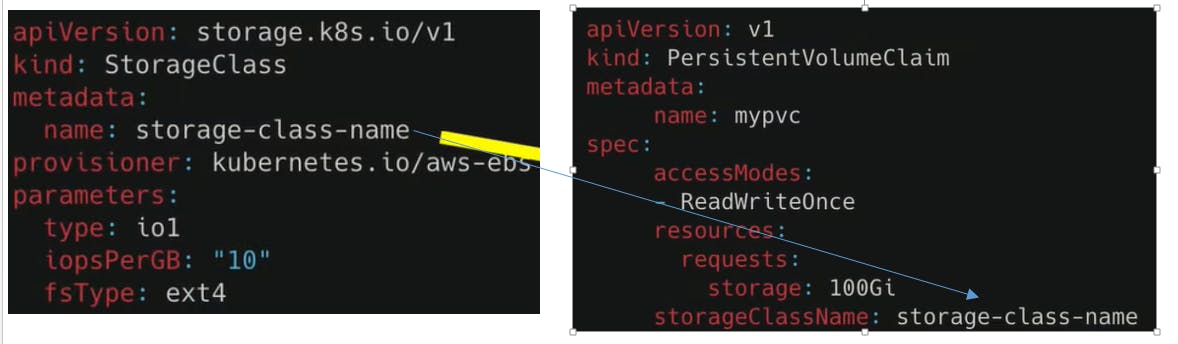
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: storage-class-name
provisioner: kubernetes.io/aws-ebs
parameters:
type: iol
topsPerGB: "10"
fsType: ext4
In this YAML file, we've created a StorageClass resource named storage-class-name with the provisioner kubernetes.io/aws-ebs. We've also set some parameters for this storage class, such as type, topsPerGB, and fsType. These parameters will be used by the provisioner to create and configure the PersistentVolume resources dynamically.
Storage class creates persistent volumes dynamically in the background.
So remember we define the storage back-end in the persistent volume component now we have to define it in the storage class component we do that using the provisional attribute.
The provisional attribute is the main part of the storage class configuration because it tells Kubernetes which provisioner to be used for a specific storage platform or cloud provider to create the persistent volume component out of it.
Each storage backend has own provisioner
internal provisioner - "kubernetes.io"
external provisioners that you have to then explicitly go and find and use that in your storage class.
configure parameters for storage we want to request for PV
So,
Storage class is another abstraction level that abstracts the underlying storage provider as well as parameters for that storage characteristics for the storage like disk type, etc
How do you use the storage class in the pod configuration?
Same as the persistent volume it is requested or claimed by PVC.
In the PVC configuration, we add an attribute that is called the storage class name that references the storage class to be used to create a persistent volume that satisfies the claims of this PVC.
Pod claims storage via PVC
PVC requests storage from SC
SC creates PV that meets the needs of the Claim
StatefulSets
What is a stateful application?
Stateful applications are all databases like MySQL,elasticsearch, MongoDB etc or any application that stores data to keep track of its state.
In other words, these are applications that track state by saving that information in some storage.
examples of stateful applications:
databases
applications that store data
What is a stateless application?
stateless applications on the other hand do not keep records of previous interactions in each request or interaction is handled as a completely new isolated interaction based entirely on the information that comes with it and sometimes stateless applications connect to the stateful application to forward those requests.
Deployment
stateless applications are deployed using the deployment component.
Deployment is an abstraction of pots and allows you to replicate that application meaning run to N number of identical parts of the same stateless application in the cluster.
Stateful applications in Kubernetes are deployed using stateful set components.
Like deployment stateful set makes it possible to replicate the stateful app, pods or to run multiple replicas of it.
In other words, they both manage pods that are based on an identical container specification. you can also configure storage with both of them equally in the same way so if both manage the replication of pots and also the configuration of data persistence in the same way.
Creating StatefulSets
To create a StatefulSet, you need to define a manifest in YAML and create the StatefulSet in your cluster using kubectl apply.
After you create a StatefulSet, it continuously monitors the cluster and makes sure that the specified number of pods are running and available.
When a StatefulSet detects a pod that failed or was evicted from its node, it automatically deploys a new node with the same unique ID, connected to the same persistent storage, and with the same configuration as the original pod (for example, resource requests and limits). This ensures that clients who were previously served by the failed pod can resume their transactions.
The following example describes a manifest file for a StatefulSet. It was shared by Google Cloud. Typically, a StatefulSet is defined together with a Service object, which receives traffic and forwards it to the StatefulSet.
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx
serviceName: "nginx"
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
terminationGracePeriodSeconds: 10
containers:
- name: nginx
image: k8s.gcr.io/nginx-slim:0.8
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumes:
- name: www
persistentVolumeClaim:
claimName: www
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 1Gi
A few important points about the StatefulSet manifest:
The code above creates a StatefulSet called
web, containing three pods running an NGINX container image.The
specs.selector.matchLabels.appfield must match thetemplate.metadata.labelsfield (both are set to app: nginx). This ensures that the StatefulSet can correctly identify containers it is managing.The pod exposes the
webport defined as port 80.volumeClaimTemplatesprovides storage using a PersistentVolumeClaim calledwww. This requests a storage volume that enablesReadWriteOnceaccess and has 1GB of storage.A mount path is specified by
template.spec.volumeMountsand is calledwww. This path indicates that storage volumes should be mounted in the/usr/share/nginx/htmlfolder within the container.
RBAC (Role-Based Access Control)
Kubernetes supports RBAC, which enables administrators to define granular permissions for users and services based on their roles and responsibilities. This feature allows administrators to control access to Kubernetes resources, including pods, nodes, and services.
In Kubernetes, ClusterRoles and Roles define the actions a user can perform within a cluster or namespace, respectively. You can assign these roles to Kubernetes subjects (users, groups, or service accounts) with role bindings and cluster role bindings.
Role In RBAC
A role in Kubernetes RBAC defines what you will do to a group of resources. It contains a group of rules which define a set of permission.
Here’s an example Role within the “default” namespace that can be used to grant read access to pods:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: default
name: pod-reader
rules:
- apiGroups: [""] # "" indicates the core API group
resources: ["pods"]
verbs: ["get", "watch", "list"]
Cluster Role In RBAC
Roles in RBAC are used to assigning resources for a namespace, however, if you wish to assign resources on a cluster level, you need to use ClusterRole.
Here is an example of a ClusterRole which will be used to grant read access to secrets in any explicit namespace, or across all namespaces (depending on how it’s bound):
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
# "namespace" omitted since ClusterRoles are not namespaced
name: secret-reader
rules:
- apiGroups: [""]
#
# at the HTTP level, the name of the resource for accessing Secret
# objects is "secrets"
resources: ["secrets"]
verbs: ["get", "watch", "list"]
Role Binding In RBAC
Role Binding in Kubernetes Role-Based Access Control is used for granting permission to a Subject in a Kubernetes cluster. Subjects are nothing but a group of users, services, or teams attempting Kubernetes API. It defines what operations a user, service, or group can perform.
Cluster Role Binding In RBAC
Cluster Role Binding in RBAC is used to grant permission to a subject on a cluster level in all the namespaces. It will offer you permissions for cluster resources and it can even offer you permissions for resources within any namespace within a cluster. Cluster role bindings are very powerful and you want to be careful with how you apply them because they apply not solely to any existing namespaces but to any future namespaces that you just might create yet.
Network policies
Kubernetes allows administrators to define Network Policies that specify rules for traffic flow within the cluster. These policies can be used to restrict traffic between pods, namespaces, or even entire clusters, based on IP addresses, ports, or other attributes.
Writing Network Policies
Like other Kubernetes resources, network policies can be defined using a language called YAML. Here’s a simple example that allows access from balance to postgress:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default.postgres
namespace: default
spec:
podSelector:
matchLabels:
app: postgres
ingress:
- from:
- podSelector:
matchLabels:
app: balance
policyTypes:
- Ingress
Once you’ve written the policy yaml, use kubectl to create the policy:
kubectl create -f policy.yaml
A network policy specification consists of four elements:
podSelector: the pods that will be subject to this policy (the policy target) - mandatory
policyTypes: specifies which types of policies are included in this policy, ingress and/or egress - this is optional but I recommend always specify it explicitly.
ingress: allowed inbound traffic to the target pods - optional
egress: allowed outbound traffic from the target pods - optional
TLS
You can secure an application running on Kubernetes by creating a secret that contains a TLS (Transport Layer Security) private key and certificate.
Currently, Ingress supports a single TLS port, 443, and assumes TLS termination.
The TLS secret must contain keys named tls. crt and tls. keys that contain the certificate and private key to use for TLS.
Create TLS Secret:
Using kubectl:
kubectl create secret tls my-tls-secret \
--key < private key filename> \
--cert < certificate filename>
Using YAML file:
---
apiVersion: v1
data:
tls.crt: "base64 encoded cert"
tls.key: "base64 encoded key"
kind: Secret
metadata:
name: my-tls-secret
namespace: default
type: kubernetes.io/tls
Ingress with TLS:
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: tls-example-ingress
spec:
rules:
-
host: mydomain.com
http:
paths:
-
backend:
serviceName: my-service
servicePort: 80
path: /
tls:
-
hosts:
- mydomain.com
secretName: my-tls-secret
Connect me on
LinkedIn: https://www.linkedin.com/in/aditya-tak/
Hashnod: https://adityatak.hashnode.dev/
#Kubernetes #Devops #Kubeweek #kubeweekchallenge
Thank You! Stay Connected☁️👩💻
Resources:
https://www.youtube.com/watch?v=0swOh5C3OVM
https://k21academy.com/docker-kubernetes/rbac-role-based-access-control/#6